Unleashing the Power of RAG with AWS Bedrock
In today’s fast-paced business world, organizations are constantly seeking ways to leverage cutting-edge technologies to streamline their operations and enhance customer experiences. Retrieval-Augmented Generation (RAG) is a game-changing approach that combines the power of large language models with the ability to retrieve relevant information from vast knowledge bases. However, implementing RAG can be a daunting task, requiring complex orchestration frameworks and the management of vector databases, embeddings, and storage.
Enter AWS Bedrock, a game-changer in the realm of RAG deployment. This innovative service from Amazon Web Services (AWS) offers a fully managed and cost-effective solution that simplifies the process of building, deploying, and maintaining RAG applications.
One of the standout features of AWS Bedrock is its seamless integration with Amazon S3 and the Bedrock console. With just a single API call from your client application, you can leverage the RAG implementation managed by Bedrock. This streamlined approach eliminates the need for complex orchestration frameworks, allowing you to focus on building compelling applications rather than grappling with the underlying infrastructure.
At the heart of AWS Bedrock lies the powerful Bedrock orchestrator, which handles the heavy lifting of querying knowledge bases stored in Amazon S3, passing context to large language models like Claude, and returning the generated response to your client application. This robust orchestration process ensures that your RAG applications can leverage the latest advancements in natural language processing while abstracting away the complexities of managing vector databases, embeddings, and storage.
A Real-World Example
To showcase the simplicity of RAG deployment with AWS Bedrock, let’s consider a real- world example. Imagine you run an a training company, AI Elevate, and you want to provide your users with a seamless experience when searching for course descriptions.
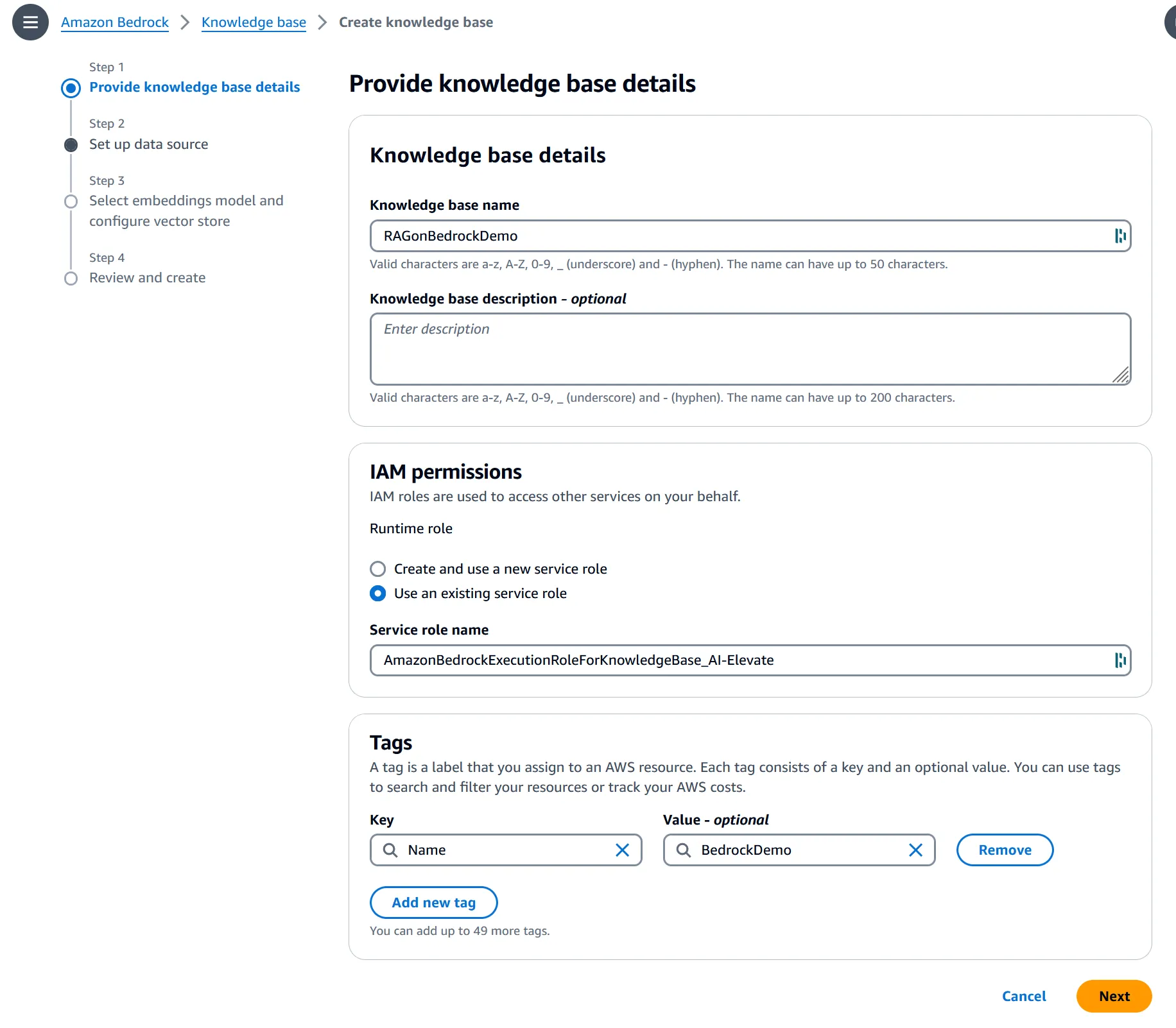
1. Create a Knowledge Base
To use AWS Bedrock, you start by creating a knowledge base in the Bedrock console:
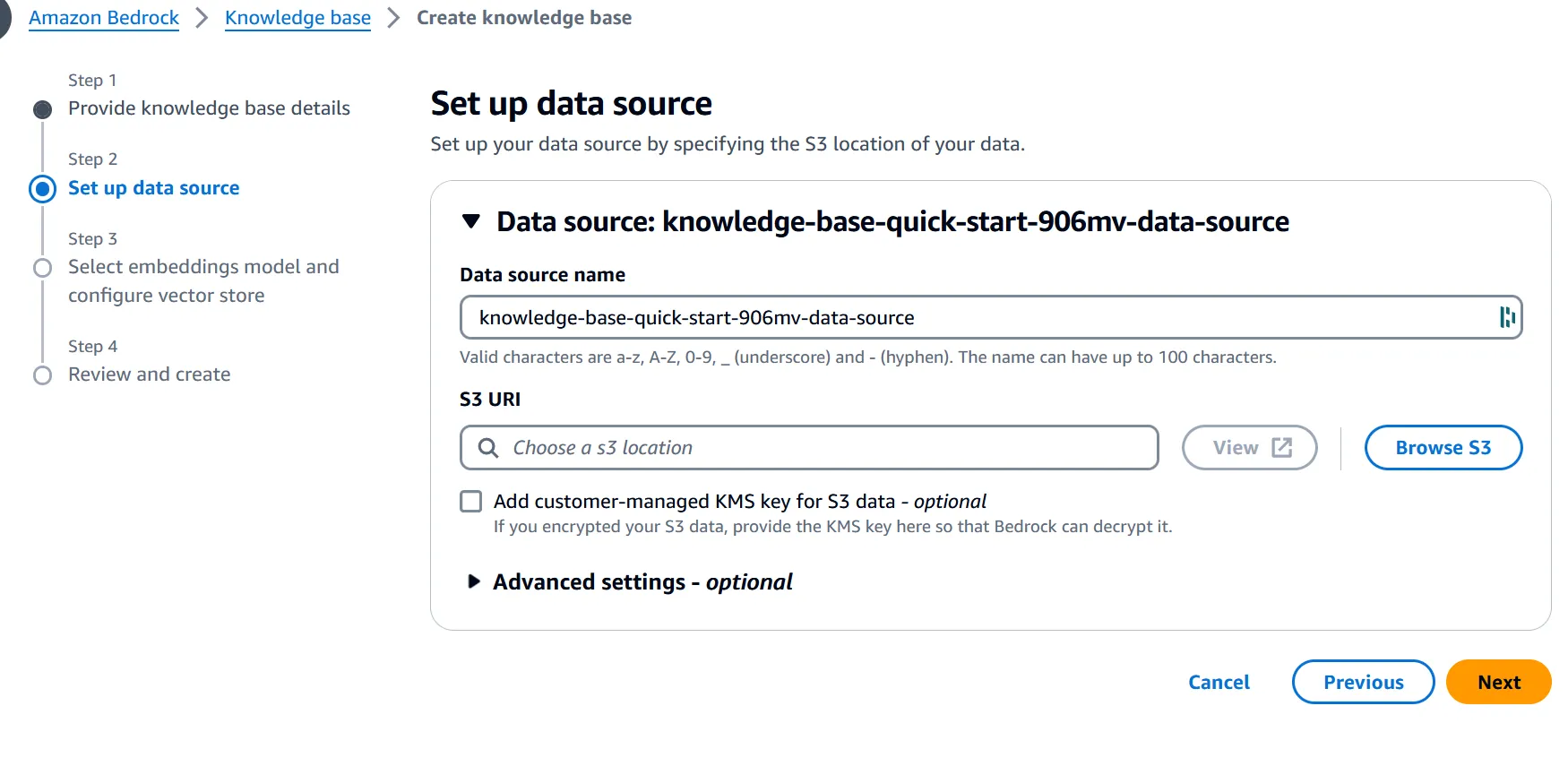
2. Setup your Vector Database
But that’s not all – AWS Bedrock also simplifies the management of your vector databases and embeddings.
With just a few clicks in the Bedrock console, you can select an Amazon S3 bucket as a source to store your documents in:
3. Choose a Vector Embedding Model
Then you choose a vector embedding model, and sync your data with the vector database manually or through automation. This level of ease and flexibility empowers you to keep your knowledge bases up-to-date effortlessly, ensuring that your RAG applications always have access to the most recent and relevant information.
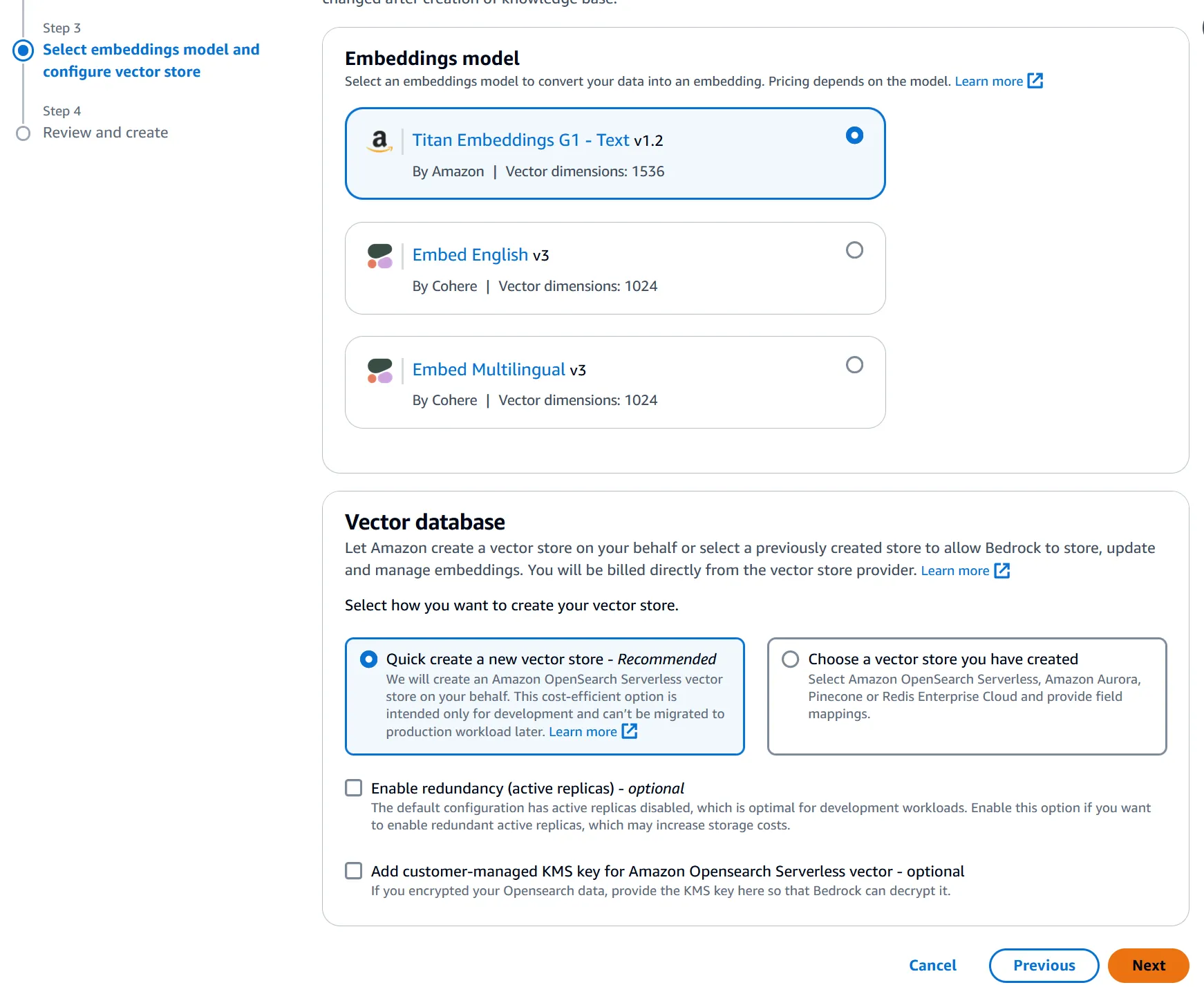
With just a few test documents detailing the course offerings loaded into the S3 bucket, the RAG system can instantly retrieve and generate relevant information based on user prompts.
If new course offerings are added by AI Elevate, you sinply add the text description to the S3 bucket and Sync the knowledge base, either via the console or via an AWS CLI command.
Testing
But this is not all – the Bedrock console also has a test option built in, so you can test your model:
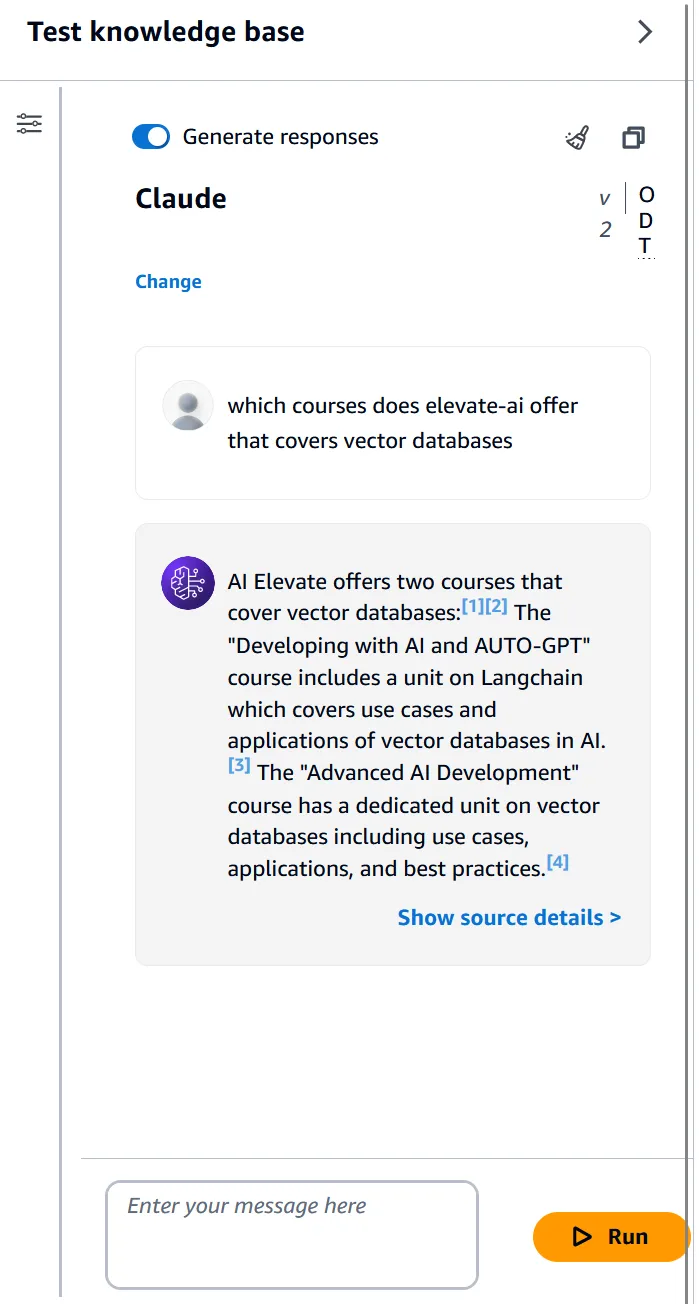
Whether a user is searching for a specific course topic or exploring related offerings, the RAG application powered by AWS Bedrock will provide accurate and contextual responses, enhancing the overall user experience.
Conclusion
In conclusion, AWS Bedrock is revolutionizing the way organizations approach RAG deployment. By eliminating the complexities of orchestration frameworks and vector embedding models, Bedrock empowers developers to focus on building innovative applications that leverage the full potential of natural language processing. With its cost- effective pricing model, seamless integration with AWS services, and user-friendly console, Bedrock is poised to become one of the go-to solution for businesses seeking to unlock the power of RAG in a streamlined and efficient manner.